Moving past the monolith, Part 4 – Using the Service Object pattern
This is part of a series of posts about Moving Past The Monolith. To start at the beginning, click here.
One of the typical characteristics of monoliths are giant classes that are grouping otherwise unrelated sets of functionality. You may find this in domain model classes (the Rails “fat model” conundrum), or in “god classes” that typically end with words like “Manager” or “Logic” that just group methods that are related to some common entity in the system.
These super-large classes don’t provide much benefit in terms of shared functionality. Many times you have small groups of methods within those classes that call each other in a little mini-system. Sometimes you have methods that are used by several other methods, but in that case you don’t know what you’re going to break when you change them. In all cases, the code tends to be difficult to change because you don’t know what the side effects will be.
The Service Object pattern is one way to solve this problem (also known as “domain services” in Domain Driven Design). There are many articles you can read that explain this concept in depth, but I’ll explain how I’ve been using it.
The backend of pretty much every application has some sort of internal API layer that is exposed to outside consumers or the UI of the application. These may be HTTP services, message queues, or just a logical separation between your UI and your business layer. However this manifests itself doesn’t matter, what’s important is that you have some place when you have a set of queries or actions that can be called by a UI or some other caller.
This API layer represents the set of capabilities that your application can perform – no more, no less. This is a description of the surface area that is exposed to the outside world. This also describes the things that I need to test.
Let’s imagine that we’re writing an application to do bank account functions. We’ll assume for this example that I’m exposing these through a .NET Web API controller.
public class AccountController
{
private IDepositService _depositService;
private IWithdrawService _withdrawService;
public AccountController(IDepositService depositService, IWithdrawService withdrawService)
{
_depositService = depositService;
_withdrawService = withdrawService;
}
[HttpPost]
[ResponseType(typeof(DepositResponse)]
public async Task<IHttpActionResult> Deposit(DepositRequest request)
{
return Ok(await _depositService.Execute(request);
}
[HttpPost]
[ResponseType(typeof(WithdrawResponse)]
public async Task<IHttpActionResult> Withdraw(WithdrawRequest request)
{
return Ok(await _withdrawService.Execute(request);
}
}
Let’s look at some of the characteristics of this controller:
- The controller methods do nothing other than call the domain service and handle HTTP stuff (return codes, methods, routes)
- Every controller method takes in a request object and returns a response object (you may have cases where this are no request parameters or no response values)
- The controller is documentation about the capabilities of the application, which you can expose with tools like Swagger and Swashbuckle (if you’re in .NET)
Now let’s move on to the domain services.
Let’s say that I have a Account domain model that looks like this:
public class Account
{
public int AccountId { get; set; }
public decimal Balance { get; private set; }
public void Deposit(decimal amount)
{
Balance += amount;
}
public void Withdraw(decimal amount)
{
Balance -= amount;
}
}
My domain service looks like this:
public class DepositService : IDepositService
{
private IRepository _repository;
public DepositService(IRepository _repository)
{
_repository = repository;
}
public async Task<DepositResponse> Execute(DepositRequest request)
{
var account = _repository.Set<Account>().Single(a => a.AccountId == request.AccountId);
account.Deposit(request.Amount);
_repository.Update(account);
return new DepositResponse { Success = true, Message = "Deposit successful" };
}
}
My domain service contains all of the code needed to perform the action. If I need to split anything out into a private method, I know that no other classes are using the same private methods. If I wanted to refactor how depositing works, I could delete the contents of the Execute() method and rewrite it and I wouldn’t have to worry about breaking anything else that could’ve been using it (which you never know when you have god classes).
You may notice that I do have some logic in the Account class. It’s still a good idea to have methods on your models that can be used to do things that will update the properties on the domain model class rather than just updating raw property values directly (but I’m not one of those people that says to never expose setters on your domain models).
I’m also using the same request and response objects that are being used by the caller. Some people like to keep the request and response objects in the controller layer and map them to business domain model objects or other business layer objects before calling the domain service. By using the request and response objects, I’m eliminating unnecessary mapping code that really has no value, which means less code, fewer tests to write, and fewer bugs.
I prefer to only have each domain service handle only one action (e.g. one public Execute() method). I’m trying to get away from the arbitrary grouping of methods in domain services where methods exist in the same class only because they’re working with the same general area of the system. You will have cases where you have multiple controller actions that are very much related and it will make sense to have multiple controller actions share a domain service. If you use common sense, you’ll know when to do this.
Testing this class is going to be pretty easy. I really only have to worry about 3 things here:
- The input
- The output
- Any database updates or calls to external services that are made in the method
Not only that, since all of the logic I want to test is encapsulated in one class, I’m not going to end up with lots of mocks or having to split up one action into multiple sets of tests that test only half of the action. I also know that my application has a finite set of capabilities, which means that I have a finite set of things to test. I know exactly how this action is going to performed.
Reducing layers
Most applications tend to have layers. The typical example (which I’m using in my example) is when you have a UI layer that calls a controller layer which calls a business layer which calls a data layer which calls a database (and then passes information back up through the layers). If you were to draw this up as a picture, the API layer of most applications would look like this:
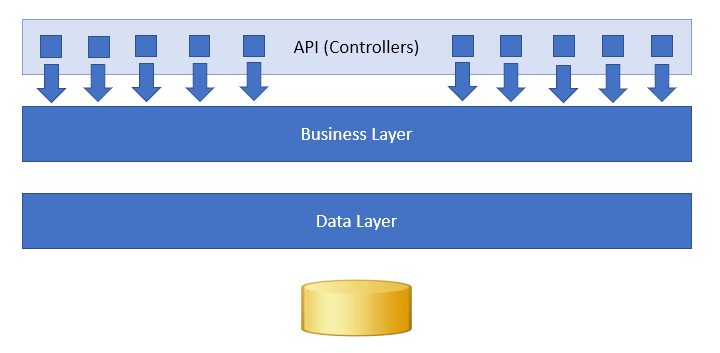
There’s a problem with this though. The picture clearly shows that the controller layer has a finite set of things it can do, but the surface area of the business layer is potentially much larger.
Some people will think of their business layer as another kind of API layer, with the consumer being the controller layer and other callers inside the business layer. The problem is that in most code bases, the business area has a very large surface area because there are many public methods that aren’t organized well. This is difficult to test because you don’t know how the business layer is going to be used, so you have to guess at write tests based on an assumption. This means that you’re probably going to not test a scenario that you should, and you will also test a scenario that is never going to happen in your application.
What this modular kind of code structure is emphasizing that our application is made up of a finite set of actions that take in inputs, modify state, and return outputs. When you structure your code in this way, your layers actually look like this:
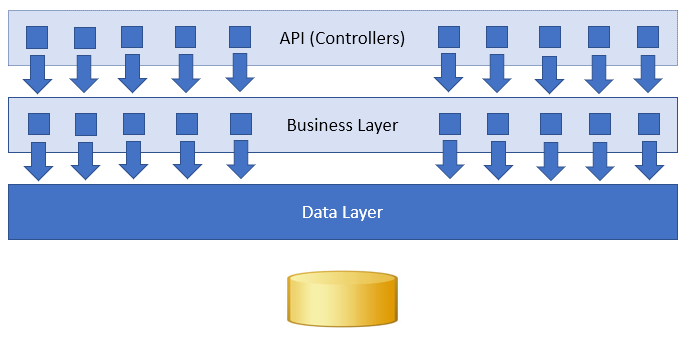
Now my business layer has a finite set of capabilities to test, I know exactly how it can be used, and my code is organized around how it will be used.
What do I do when my domain services need to share code?
If my domain service objects are going to use all of these different request/response objects as inputs and outputs, what happens when multiple domain services need to share code?
In our codebase, we have “helper” classes that perform these shared actions (when I can’t put the code on the domain models themselves). A good example would a SendEmailHelper class that takes care of sending emails, which is something that many domain services might want to do.
There is an intricacy here to consider — if you split something out into a helper class, do you want to mock out that helper class in a unit test? There are times when you do and times when you don’t. If you’re sending an email (which interacts with an external SMTP server), you likely would mock out the SendEmailHelper in your domain service tests and then write separate tests for the SendEmailHelper. Sometimes you might have a helper class that exists because it’s shared code, but you want to be able to write unit tests that test the entire mini-system of your domain service action. In this case, it’s totally OK to new up the concrete helper class and use that in your test. Not every external dependency needs to be mocked out in a test, sometimes mocks are the wrong way to go.
My big thing is that I want the unit tests for my domain services to effectively test the spirit of what the domain service is supposed to do. I have had cases where I’ve run across code that was split out into so many helper classes (many of which were only used by the domain service) and unit testing becomes really difficult because your tests have so many mocks, and each test class feels like it’s testing only part of what the domain service does. If you run into this sinking feeling, maybe you should reconsider how you’re writing your tests or organizing your code.
Isn’t this the classic anemic domain model anti-pattern?
I don’t think we’re violating the spirit of the rule here. I agree that there should still be things that you put on the domain model objects themselves, such as validation rules (required fields, string lengths, other business validation rules), calculations (e.g. FullName = FirstName + ” ” + LastName), and methods used to modify properties (e.g. our Deposit() example).
This is a good example of using common sense, because thousands of Rails developers screamed at the thought of an anemic domain models and then ended up with fat models instead, which (IMO) is a bigger problem.
Object-oriented programming is not a panacea
Object-oriented programming is often talked about as the “best” way to write code, but that doesn’t mean that everything has to be OO. Procedural programming is often associated with negative things like giant stored procs and legacy VB codebases, but that doesn’t mean that all procedural code is bad. The approach I’ve outlined is still based in object-oriented programming, but it involves more procedural code and embraces the fact that our applications are a collection of procedures based around a rich set of objects. I’m doing this because it’s a conscious decision to move more towards modularity, maintainability, and easier testing.
Read the next post in this series, Minimizing sharing between modules.

Hi Jon,
I highly recommend a study on onion architecture (http://jeffreypalermo.com/blog/the-onion-architecture-part-1/) as well as SOLID principles. If you can get a solid understanding of these two concepts they will lend invaluable to extensible domain driven back-end designs.
A few notes on your posted code-blocks:
On your first code block –
WebApi supports REST implicitly. Instead of marking methods with attributes, you can simply do something like this:
public async Task Put(Request request) { … }
Also, if withdraw and deposit are different enough to require independent services, perhaps you have two different concerns/resources, therefore two different REST endpoints ie (POST|PUT|DELETE) /whatever/deposit, (POST|PUT|DELTE) /whatever/withdraw
On your second code block, I would recommend returning objects/values when possible. Void methods can be difficult to test and make debugging tougher because it’s harder to find where the object was changed.
And some comments on your writing:
“I agree that there should still be things that you put on the domain model objects themselves, such as validation rules”
If by “put on” you mean add validation attributes, I’ll have to disagree. With the assumption you’re using a code-first design with EF, you can remove the dependencies the attributes create from your domain model project.
If you use EF’s fluent configuration, you can add the attributes in the mapping config instead – separating logic and dependencies from your domain models.
“Procedural programming is often associated with negative things like giant stored procs and legacy VB codebases, but that doesn’t mean that all procedural code is bad”
Procedural code is what turns once object oriented code into god classes. Does procedural code have it’s place? Sure, but not in an object oriented library. If procedural code fits the bill the best, you likely have a separate concern than the one at hand. Your procedural implementation likely needs to live in it’s own assembly.
“if you split something out into a helper class, do you want to mock out that helper class in a unit test? There are times when you do and times when you don’t”
The email helper you described is not a helper but a domain service. Domain services don’t have to touch domain models. Domain services provide core logic your domain needs to function. This is one reason why we don’t combine domain models with domain services in the same class.
Good luck